ChatGPT (viết tắt của Chat Generative Pre-trained Transformer) là một chatbot AI dựa trên mô hình ngôn ngữ lớn do OpenAI phát triển và ra mắt vào ngày 30/11/2022. Về cốt lõi, ChatGPT được xây dựng trên kiến trúc Transformer với phiên bản mô hình GPT-3.5 (và các phiên bản sau đó như GPT-4). Điều này cho phép ChatGPT hiểu ngôn ngữ tự nhiên và tạo ra văn bản giống như con người trong nhiều ngữ cảnh khác nhau. Bên cạnh nền tảng kỹ thuật, ChatGPT còn được tinh chỉnh thông qua các giai đoạn huấn luyện đặc biệt để tuân thủ hướng dẫn và ưu tiên phản hồi của con người, làm cho nó trở thành một trợ lý ảo hữu ích trong nhiều lĩnh vực đời sống.
Dưới đây, chúng ta sẽ đi sâu vào các thành phần chính đằng sau ChatGPT – từ kiến trúc Transformer, cơ chế token hóa, attention, cho đến quy trình huấn luyện (tiền huấn luyện, tinh chỉnh và RLHF), cũng như cách mô hình sinh ra văn bản. Song song đó, bài viết cũng đề cập đến ứng dụng thực tiễn của ChatGPT trong các lĩnh vực như trợ lý ảo, sáng tạo nội dung, hỗ trợ học tập... để thấy được sự cân bằng giữa yếu tố kỹ thuật và lợi ích phổ thông.
Kiến trúc mô hình Transformer
Transformer là kiến trúc mạng nơ-ron chuyên xử lý dữ liệu tuần tự, nổi bật nhờ cơ chế tự chú ý (self-attention). Thay vì sử dụng mạng hồi quy (RNN) hoặc mạng tích chập (CNN) tuần tự như trước đây, Transformer loại bỏ hoàn toàn tính tuần tự cố hữu và sử dụng multi-head self-attention để mô hình hóa quan hệ ngữ cảnh giữa các token trong chuỗi đầu vào. Cụ thể, trong mô hình gốc (phiên bản Transformer cho dịch máy), Transformer gồm hai khối encoder và decoder, nhưng GPT sử dụng kiến trúc decoder-only – tức chỉ bao gồm các tầng decoder xếp chồng lên nhau.
Mỗi decoder layer trong GPT bao gồm: (1) một lớp masked self-attention đa đầu để cho phép mỗi token đầu ra chú ý đến các token trước nó (nhưng không nhìn thấy tương lai), và (2) một mạng feed-forward (MLP) áp dụng độc lập cho từng vị trí. Giữa các lớp này còn có cơ chế residual connections và layer normalization giúp ổn định việc huấn luyện. Trước khi đi qua các tầng decoder, chuỗi token đầu vào được chuyển thành vector thông qua lớp Embedding và được bổ sung thông tin vị trí nhờ Positional Encoding (vì mô hình không có tính tuần tự cố hữu nên cần mã hóa vị trí). Kết thúc chuỗi decoder, mô hình dùng một lớp Linear kết hợp với hàm Softmax để xuất ra phân phối xác suất trên toàn bộ vocab (tập hợp từ vựng các token). Nói một cách đơn giản, tại mỗi bước mô hình sẽ ước tính xác suất cho từng token khả dĩ tiếp theo.
Nhờ kiến trúc attention song song, Transformer (và GPT) có thể xử lý thông tin hiệu quả hơn trên các chuỗi dài so với mô hình tuần tự truyền thống. Cơ chế tự chú ý cho phép mô hình “nhìn” toàn bộ ngữ cảnh đầu vào: mỗi từ trong câu có thể tương tác trực tiếp với các từ khác, thay vì phải qua từng bước tuần tự. Điều này giải quyết hạn chế của RNN khi xử lý ngữ cảnh xa. Chẳng hạn, khi mô hình đọc câu "Con mèo nhảy lên thảm rồi nó nằm ngủ", self-attention giúp mô hình hiểu được từ "nó" liên quan đến "con mèo" chứ không phải vật nào khác trong câu. Nhờ đó, mô hình giữ được ngữ nghĩa thống nhất và quan hệ phụ thuộc đường dài trong văn bản. Transformer cũng cho phép tính toán song song, giúp huấn luyện trên tập dữ liệu cực lớn trở nên khả thi và nhanh hơn nhiều so với mô hình tuần tự.
Tóm lại, kiến trúc Transformer chính là “bộ não” của ChatGPT, cung cấp nền tảng để mô hình có thể hiểu và sinh ngôn ngữ tự nhiên một cách linh hoạt. Tiếp theo, chúng ta sẽ tìm hiểu cách văn bản được biểu diễn và xử lý trong mô hình thông qua cơ chế token hóa và attention chi tiết hơn.
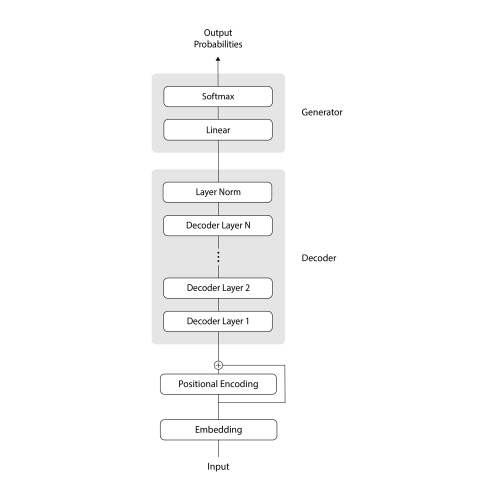
Hình 1: Sơ đồ kiến trúc tổng quan của mô hình GPT (Transformer decoder). Mỗi decoder layer gồm các khối attention và feed-forward, với thông tin vị trí được thêm qua Positional Encoding. Đầu ra cuối cùng được đưa qua lớp Linear + Softmax để tạo phân phối xác suất cho token tiếp theo.
Cơ chế token hóa
Trước khi văn bản được đưa vào mô hình Transformer, nó cần được chuyển đổi thành các token số hóa – đây là nhiệm vụ của bộ token hóa (tokenizer). ChatGPT sử dụng phương pháp Byte Pair Encoding (BPE) để mã hóa văn bản thành các token. Thay vì coi mỗi từ là một token như cách làm truyền thống, BPE sẽ tách văn bản thành các cặp ký tự/phần từ phổ biến. Ban đầu, tất cả các ký tự riêng lẻ (chữ cái, dấu câu, khoảng trắng, v.v.) đều là token. Sau đó thuật toán BPE sẽ lặp lại việc tìm cặp token xuất hiện thường xuyên nhất và gộp chúng thành một token mới. Quá trình này lặp lại cho đến khi đạt đến kích thước từ vựng mong muốn. Kết quả là ta có một tập token bao gồm cả những từ đơn giản và các tiểu từ (subword) phổ biến.
Trong trường hợp GPT-3.5/GPT-4 của ChatGPT, kích thước từ vựng token lên tới khoảng 100.000 token. Nhờ bộ token hóa BPE, mô hình có thể biểu diễn hầu như mọi từ trong ngôn ngữ (kể cả từ hiếm hoặc từ mới) dưới dạng chuỗi các token đã biết. Ví dụ, một từ dài hoặc không phổ biến có thể được chia thành vài token subword. Điều này giúp mô hình vừa không bị giới hạn ở từ vựng cố định, vừa tránh việc phải xử lý chuỗi token quá dài (vì các từ phổ biến đã được gộp lại).
Sau khi token hóa, mỗi token (là một số nguyên đại diện) sẽ được ánh xạ thành vector nhờ lớp Embedding trong mô hình. Tập hợp các vector này chính là đầu vào thực sự cho kiến trúc Transformer. Tóm lại, cơ chế token hóa đảm bảo chuyển đổi linh hoạt giữa văn bản và dạng số, giúp ChatGPT xử lý được văn bản ở cấp độ thấp nhất và tổng quát hóa cho những từ ngữ chưa gặp trong quá trình huấn luyện.
Cơ chế Attention trong Transformer
Attention (cơ chế chú ý) là thành phần cốt lõi làm nên sức mạnh của Transformer. Hiểu đơn giản, attention cho phép mô hình tập trung vào các phần quan trọng của ngữ cảnh khi xử lý hoặc sinh ra một token nào đó. Trong ChatGPT, mỗi token đầu ra được sinh ra không chỉ dựa trên token ngay trước nó, mà dựa trên toàn bộ chuỗi ngữ cảnh trước đó thông qua cơ chế self-attention.
Quá trình self-attention diễn ra như sau: giả sử tại một bước tạo từ, mô hình có một tập các vector biểu diễn các token trước đó. Mỗi vector này sẽ được biến đổi thành Query (truy vấn), Key (khóa) và Value (giá trị) thông qua các phép chiếu tuyến tính độc lập. Sau đó, điểm chú ý giữa token đang xét (Query) với mỗi token ngữ cảnh (Key) được tính bằng tích chấm có trọng số (scaled dot-product). Điểm này càng cao nghĩa là token ngữ cảnh đó càng quan trọng đối với việc dự đoán token tiếp theo. Các điểm chú ý được chuẩn hóa (qua Softmax) để tạo thành trọng số attention. Cuối cùng, mô hình tổng hợp các Value (những thông tin của các token ngữ cảnh) lại, có trọng số theo mức độ quan trọng vừa tính, để thu được ngữ cảnh đã trọn lọc cho token hiện tại.
Transformer sử dụng Multi-Head Attention nghĩa là lặp lại phép tính attention trên nhiều “đầu” độc lập, mỗi đầu có thể học một khía cạnh quan hệ khác nhau (ví dụ một đầu học về quan hệ ngữ pháp, một đầu khác học về chủ đề). Kết quả từ các đầu được ghép lại (concatenate) và qua một lớp linear để cho đầu ra cuối cùng của lớp attention. Nhờ đa đầu chú ý, mô hình có khả năng học được nhiều loại ngữ cảnh đa dạng cùng lúc, tăng cường hiểu biết ngôn ngữ.
Trong ChatGPT, attention giúp mô hình duy trì được tính mạch lạc của đoạn hội thoại. Ví dụ, nếu người dùng hỏi: "Hôm nay trời mưa, bạn có gợi ý gì cho tôi?", mô hình sẽ chú ý đến từ khóa "trời mưa" và ngữ cảnh "gợi ý gì" để tạo ra câu trả lời phù hợp (chẳng hạn gợi ý về các hoạt động trong nhà khi trời mưa). Cơ chế attention đảm bảo rằng thông tin ở đầu vào được truyền đến đầu ra một cách có chọn lọc và thông minh, giúp câu trả lời của ChatGPT liên kết chặt chẽ với câu hỏi người dùng.
Tóm lại, attention như “ánh đèn sân khấu” – nó soi chiếu vào những phần quan trọng nhất của ngữ cảnh để mô hình tập trung xử lý, từ đó tạo ra đầu ra chính xác và phù hợp. Đây chính là yếu tố giúp ChatGPT hiểu đúng ý người hỏi và giữ được mạch logic trong các câu trả lời dài.
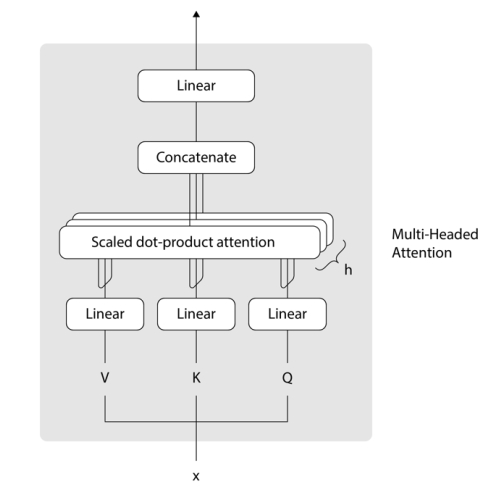
Hình 2: Sơ đồ khối của cơ chế Multi-Head Attention (đa đầu chú ý) trong Transformer. Đầu vào $x$ (các vector ẩn) được nhân qua ba ma trận trọng số (Linear) để tạo thành Query (Q), Key (K), Value (V). Cơ chế Scaled Dot-Product Attention tính điểm chú ý dựa trên Q và K để trộn các giá trị V tương ứng. Nhiều “đầu” attention (h) chạy song song, kết quả được nối lại (Concatenate) và qua một lớp Linear cuối để tạo đầu ra.
Quá trình huấn luyện mô hình ChatGPT
Quá trình huấn luyện phía sau ChatGPT diễn ra qua ba giai đoạn chính: (1) Tiền huấn luyện trên lượng dữ liệu khổng lồ, (2) Tinh chỉnh có giám sát (supervised fine-tuning) trên dữ liệu đặc thù, và (3) Huấn luyện tăng cường từ phản hồi người dùng (Reinforcement Learning from Human Feedback - RLHF). Mỗi giai đoạn đóng một vai trò quan trọng trong việc hình thành nên trí thông minh và tính hữu ích của ChatGPT.
Giai đoạn 1: Tiền huấn luyện trên dữ liệu diện rộng
Tiền huấn luyện (Pre-training) là bước đầu tiên, trong đó mô hình GPT được huấn luyện trên khối lượng văn bản khổng lồ từ Internet (ví dụ: sách, bài báo, website, diễn đàn). Mục tiêu của tiền huấn luyện là học cách dự đoán từ tiếp theo trong một đoạn văn bất kỳ – tức là mô hình hóa phân phối ngôn ngữ. Cụ thể, mô hình được cung cấp một chuỗi từ và phải dự đoán từ kế tiếp là gì. Ví dụ, nếu mô hình thấy đoạn "Con mèo đang...", mô hình có thể dự đoán tiếp theo là "...ngủ trên thảm.". Quá trình này giống như bạn liên tục đoán chữ khi đọc dở câu trong một quyển sách.
Sau hàng tỷ tỷ lần học dự đoán như vậy, mô hình dần tích lũy một lượng kiến thức ngôn ngữ rộng lớn: nó biết cú pháp, ngữ pháp và có cả kiến thức thực tế từ dữ liệu huấn luyện. Tuy nhiên, do mục tiêu chỉ là đoán từ kế, một mô hình GPT thuần túy (như GPT-3 trước đây) thường có xu hướng viết tiếp nội dung một cách máy móc hơn là thực sự đáp ứng đúng yêu cầu người dùng. Chẳng hạn, nếu đưa vào mô hình GPT-3 câu hỏi "Giải thích hiện tượng mưa là gì?", mô hình tiền huấn luyện có thể chỉ đơn thuần tiếp tục với nội dung không liên quan hoặc liệt kê các câu hỏi tương tự, thay vì trả lời trực tiếp câu hỏi. Điều này xảy ra vì tại thời điểm tiền huấn luyện, mô hình chưa được dạy phải tuân thủ mệnh lệnh hay tương tác kiểu hội thoại – nó chỉ biết dự đoán sao cho văn bản có vẻ hợp lý mà thôi.
Kết thúc giai đoạn pre-training, ChatGPT có một nền tảng kiến thức mạnh và khả năng sinh văn bản lưu loát. Nhưng để biến nó thành một trợ lý biết lắng nghe người dùng, cần có bước tinh chỉnh đặc biệt tiếp theo.
Giai đoạn 2: Tinh chỉnh có giám sát (Supervised Fine-tuning)
Ở giai đoạn tinh chỉnh có giám sát (SFT), mô hình GPT tiền huấn luyện sẽ được huấn luyện thêm trên một tập dữ liệu nhỏ hơn, do con người chuẩn bị thủ công, nhằm dạy cho mô hình cách thực hiện các nhiệm vụ cụ thể theo yêu cầu. Cách làm là tập hợp một loạt các cặp prompt - phản hồi mẫu: ví dụ prompt là một câu hỏi hoặc mệnh lệnh của người dùng, và phản hồi mẫu là câu trả lời chất lượng cao do con người viết ra. Bộ dữ liệu này được gọi là dữ liệu minh họa (demonstration data).
Các kỹ sư OpenAI đã chuẩn bị hai nguồn chính cho dữ liệu tinh chỉnh: (1) Họ tự nghĩ ra câu hỏi và câu trả lời mẫu, và (2) lấy các câu hỏi thực từ người dùng (thông qua nền tảng API của GPT-3) rồi nhờ người viết câu trả lời chất lượng. Mặc dù tập dữ liệu này tương đối nhỏ (khoảng vài chục ngàn mẫu), nhưng chúng có độ tin cậy cao và đa dạng về lĩnh vực. Sau đó, mô hình GPT tiền huấn luyện sẽ được huấn luyện lại trên bộ dữ liệu này – về cơ bản là điều chỉnh các trọng số mô hình để bắt chước cách con người trả lời cho từng loại câu hỏi. Kết quả thu được là một mô hình đã tinh chỉnh (gọi là SFT model) biết tuân thủ hướng dẫn hơn hẳn: nếu người dùng hỏi một câu, mô hình sẽ cố gắng trả lời đúng vào trọng tâm câu hỏi đó.
Tuy nhiên, do giới hạn về số lượng dữ liệu tinh chỉnh (việc nhờ người tạo dữ liệu rất tốn kém và chậm), mô hình SFT vẫn chưa hoàn hảo. Nó có thể chưa bao quát hết mọi kiểu hỏi, đôi lúc trả lời còn lan man hoặc chưa thực sự ưu tiên lợi ích người dùng. Chẳng hạn, mô hình có thể vẫn mắc lỗi “ảo tưởng” (hallucination) – tự tin tạo ra thông tin sai. Để khắc phục, nhóm OpenAI tiếp tục bổ sung giai đoạn thứ ba với sự tham gia sâu hơn của phản hồi con người.
Giai đoạn 3: Huấn luyện tăng cường từ phản hồi (RLHF)
Reinforcement Learning from Human Feedback (RLHF) là bước đột phá giúp ChatGPT căn chỉnh mục tiêu gần hơn với mong muốn của con người. Giai đoạn này gồm hai bước liên tiếp:
Bước 3a: Huấn luyện mô hình phần thưởng (Reward Model – RM). Thay vì yêu cầu con người viết câu trả lời hoàn hảo (như bước SFT), ở bước này, mô hình SFT sẽ tự tạo ra nhiều câu trả lời cho cùng một prompt. Sau đó, những người đánh giá sẽ đọc và xếp hạng các câu trả lời đó từ tốt đến kém. Ví dụ, với prompt "Viết một đoạn văn giới thiệu bản thân", mô hình có thể tạo 4 đoạn văn, và người đánh giá sắp xếp chúng theo chất lượng từ cao đến thấp. Kết quả thu được một bộ dữ liệu gồm các cặp phản hồi và thứ hạng ưu tiên do con người gán. Dựa vào đó, ta huấn luyện một mô hình phần thưởng sao cho: nhập vào một phản hồi, mô hình này xuất ra một điểm số thể hiện mức độ phản hồi được con người ưa thích. Nói cách khác, mô hình phần thưởng học cách đánh giá chất lượng câu trả lời tương tự như người.
Bước 3b: Tinh chỉnh mô hình bằng học tăng cường (với thuật toán PPO). Đây là bước cuối cùng: sử dụng mô hình phần thưởng vừa được huấn luyện làm “người hướng dẫn” để tiếp tục tinh chỉnh mô hình SFT (giờ đóng vai trò chính sách – policy trong thuật toán RL). Cụ thể, thuật toán Proximal Policy Optimization (PPO) sẽ điều chỉnh các trọng số của mô hình chatbot nhằm tối đa hóa điểm thưởng do mô hình phần thưởng cung cấp. Mô hình chatbot (policy) sẽ tạo phản hồi cho một loạt prompt, mô hình phần thưởng đánh giá mỗi phản hồi (cho điểm cao nếu phản hồi tốt theo ý người dùng, điểm thấp nếu phản hồi kém hoặc độc hại), và PPO điều chỉnh mô hình chatbot để những lần sau nó tạo ra phản hồi được điểm cao hơn. Quá trình này được lặp đi lặp lại rất nhiều lần. Đồng thời, để tránh việc mô hình chatbot tối ưu thái quá theo mô hình phần thưởng (dẫn đến phản hồi nghe có vẻ hợp ý nhưng thực chất vô nghĩa), một hệ số phạt dựa trên độ lệch so với mô hình gốc (KL-divergence penalty) được đưa vào hàm thưởng. Điều này đảm bảo mô hình sau cùng vẫn giữ được sự mạch lạc và đa dạng như mô hình tiền huấn luyện ban đầu, chỉ khác là phản hồi đã thân thiện và hữu ích hơn.
Kết quả của RLHF là một mô hình ChatGPT được “vỗ béo” bởi phản hồi của con người – nó không chỉ nói cho đúng ngữ pháp, mà còn biết ưu tiên sự hữu ích, trung thực và vô hại. Đây chính là bí quyết giúp ChatGPT thường đưa ra câu trả lời làm hài lòng người dùng, biết từ chối những yêu cầu không phù hợp, và nói chung là cư xử “có ý thức” hơn so với các mô hình trước đây.
Kết luận
Sự thành công của ChatGPT đến từ việc kết hợp kiến trúc Transformer hiện đại với một quy trình huấn luyện công phu và khối lượng dữ liệu khổng lồ. Từ cơ chế tự chú ý giúp hiểu ngữ cảnh đến việc tinh chỉnh bằng phản hồi của con người để tạo ra những phản hồi hữu ích, tất cả đều góp phần tạo nên một mô hình ngôn ngữ thông minh và linh hoạt. Không chỉ dừng ở mặt kỹ thuật, ChatGPT đã và đang chứng minh giá trị thực tiễn qua hàng loạt ứng dụng – trở thành trợ lý ảo, người viết nội dung, người hỗ trợ học tập, lập trình viên phụ tá, và nhiều vai trò khác trong cuộc sống số.
Tất nhiên, ChatGPT không phải hoàn hảo: mô hình đôi khi còn mắc lỗi, có thể đưa ra thông tin chưa chính xác hoặc phản hồi thiếu phù hợp nếu bị khai thác. Nhưng với mỗi phiên bản cải tiến, cùng với phản hồi từ cộng đồng người dùng, ChatGPT ngày càng được hoàn thiện hơn. Quan trọng hơn, sự ra đời của ChatGPT đã mở ra kỷ nguyên mới cho trí tuệ nhân tạo sáng tạo, nơi mà tương tác người-máy trở nên gần gũi hơn bao giờ hết.
Trong tương lai, với sự phát triển của AI và sự kết hợp với các lĩnh vực khác (như thị giác máy tính, robotics), chúng ta có thể kỳ vọng các mô hình như ChatGPT sẽ còn mạnh mẽ và đa năng hơn nữa. Điều đó đặt ra cả cơ hội lẫn thách thức – nhưng chắc chắn một điều rằng hiểu rõ cách những mô hình này hoạt động sẽ giúp chúng ta ứng dụng chúng một cách hiệu quả và có trách nhiệm.
Cơ chế sinh văn bản của ChatGPT
Sau khi được huấn luyện hoàn chỉnh, ChatGPT hoạt động theo nguyên tắc khá trực quan: dự đoán từng token một để hình thành câu trả lời từng bước. Cụ thể, khi người dùng nhập một prompt (có thể là câu hỏi hoặc mệnh lệnh), mô hình sẽ xử lý prompt đó và bắt đầu sinh ra phản hồi từng token nối tiếp nhau. Mỗi lần mô hình chỉ xuất một token tiếp theo dựa trên toàn bộ ngữ cảnh (prompt gốc + các token đã sinh ra trước đó). Token mới này lại được ghép vào chuỗi phản hồi, rồi mô hình tiếp tục dự đoán token kế tiếp, và quá trình lặp lại cho đến khi kết thúc (gặp ký hiệu kết thúc hoặc đạt độ dài tối đa).
Ví dụ, với câu hỏi: "Trình bày cách hoạt động của ChatGPT.", giả sử mô hình bắt đầu sinh: "ChatGPT hoạt động dựa trên...". Sau khi sinh ra từ "dựa", mô hình sẽ lấy cả đoạn "ChatGPT hoạt động dựa" làm ngữ cảnh (cùng với prompt ban đầu) để dự đoán từ tiếp theo "trên". Quá trình này giống như người đang viết văn: viết xong một chữ lại đọc cả câu để nghĩ chữ tiếp theo. Nhờ cơ chế attention, ở mỗi bước sinh, mô hình luôn xét đến toàn bộ nội dung đã có nhằm đảm bảo câu trả lời nhất quán và đúng ý.
Điểm đặc biệt là ChatGPT có thể điều chỉnh độ “sáng tạo” của đầu ra thông qua tham số như temperature hoặc top-p sampling trong quá trình sinh. Nếu chọn chiến lược tham lam (temperature thấp, mô hình luôn chọn token có xác suất cao nhất), câu trả lời sẽ ổn định và sát với dữ liệu huấn luyện. Còn nếu tăng temperature (cho phép chọn các token xác suất thấp hơn đôi chút), mô hình có thể tạo ra các phản hồi đa dạng hoặc giàu tính sáng tạo hơn. Trong thực tế, ChatGPT thường được cấu hình để giữ cân bằng – đủ ngẫu nhiên để không lặp từ, nhưng cũng đủ chắc chắn để không nói năng lạc đề.
Một cơ chế nữa giúp đảm bảo chất lượng đầu ra là dừng khi hoàn thành ý. ChatGPT được huấn luyện để nhận biết khi nào một câu trả lời đã đầy đủ. Nếu người dùng hỏi một câu đơn giản, mô hình sẽ kết thúc sau một đoạn ngắn. Ngược lại, với những yêu cầu phức tạp, mô hình có thể sinh nội dung rất dài nhưng vẫn cố gắng kết luận vấn đề hoặc hỏi lại người dùng nếu cần thêm thông tin. Điều này tạo cảm giác tương tác tự nhiên như trong hội thoại giữa người với người.
Tóm lại, quá trình sinh văn bản của ChatGPT là sự kết hợp giữa nền tảng xác suất (dự đoán token theo phân phối học được) và các điều chỉnh heuristic để phản hồi trôi chảy, mạch lạc. Đó là lý do vì sao ChatGPT có thể trả lời gần như ngay lập tức bằng những đoạn văn rõ ràng, đúng ngữ pháp và phù hợp ngữ cảnh.
Hình 3: Minh họa quá trình sinh văn bản theo kiểu “cửa sổ mở rộng dần”. Mô hình bắt đầu với đầu vào "A long time ago" (in), sinh ra token "in" (out) tiếp theo. Sau đó, đầu vào được mở rộng bao gồm cả token vừa sinh, và mô hình tiếp tục dự đoán token kế tiếp "a", cứ thế chuỗi văn bản được xây dựng dần dần.